June 12th, 2026
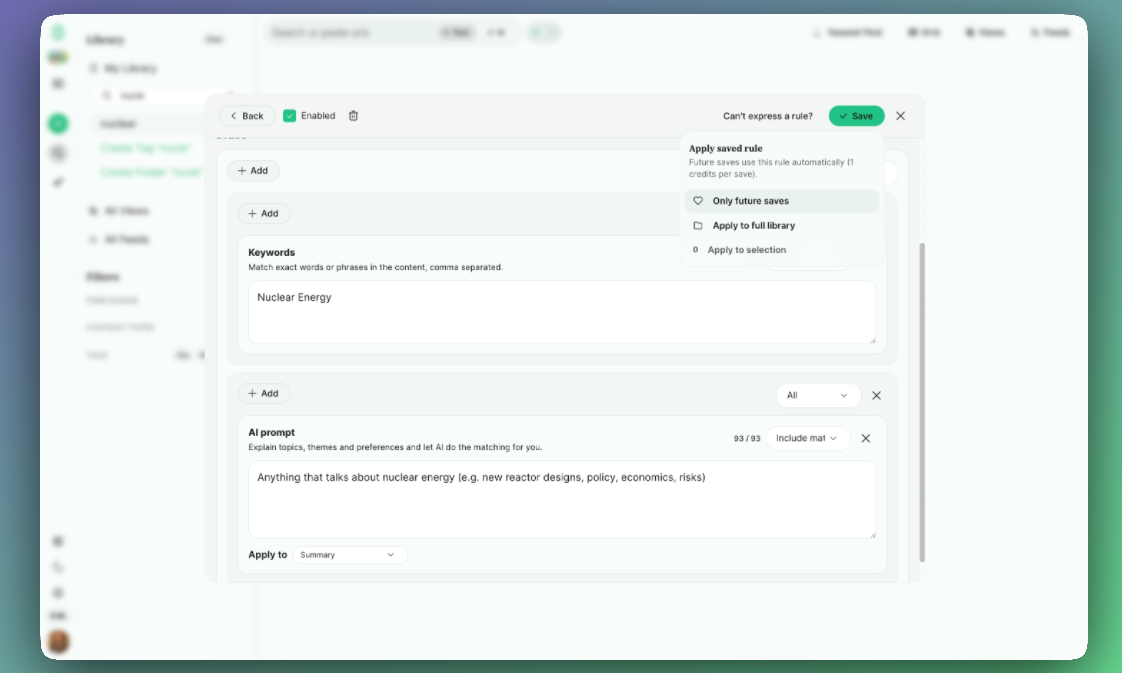
You can now create elaborate rules on how to tag content you save or that enters your feeds with keywords and AI prompts.
This means:
Less need for manually tagging stuff with high level of control and precision
A system for sorting incoming feed posts from your favourite Youtube channels, blogs, Substacks and Subreddits for the gems that really matter to you
(feed support is functional but in pre-release state and can be toggled on in the settings > feature flags for beta users (reach out in the help chat to get upgraded). Appreciate any bug reports via the help chat)

Features
Auto-tagging by keywords, content type, [free]
Use keyword matching to auto-tag items.
Pricing: Free
Auto-tagging with LLM query [Pay as you go credits]
You can define custom prompts to take actions on a piece of content.
E.g. “Anything that talks about nuclear energy (e.g. new reactor designs, policy, economics, risks)”
Pricing:
Summary level: 1 credit per 500 total prompt characters (across all prompts) per piece of content
E.g. saving 100 pieces of content with a total of 1000 prompt characters: 200 credits
Deep level, full content analysis: Additional 1 credit per 1000 tokens of content (about 4000 characters)
E.g. saving or receiving 100 pieces with total of 4000 characters each and 1000 prompt characters: 200 + 200 = 400 credits
Backfill your library
When adding a new tag you can always choose to retroactively apply the tag to your your entire library. Anything already tagged with the tag will be skipped.
Easter eggs / previews
Over the past 1.5 months we have been shipping a bunch of stuff that i am about to write change logs for. So if you’re playing around you can already find some of them. Others will be fully available in a few day when I polished them up. (If you find bugs, please report via the help chat, i am actively hunting for them and fixing them up right away)
Mobile App to save, annotate, summarize & search
Summarizing X posts and videos from the timeline
Sharing Annotated pages
PDF annotation on mobile and desktop
@mentions on x to summarize/transcribe/translate
Sharing Views
Collaborative Views
Kindle import & sync
Readwise import & sync
RSS feeds: Follow, search and auto-tag incoming items
Importing YouTube channels
Importing everything from a page
Public Library so you can share publishable repositories of your work
Note to all Memex v1 users
If you’re just now coming back, Memex v2 is a completely new system. So sign up again, and if you had a lifetime plan prior, let me know via the help chat and I’ll upgrade you right away.
Either way, your existing data we will migrate over in the coming weeks, as our new data model stabilises (which we are almost there!)
June 5th, 2026
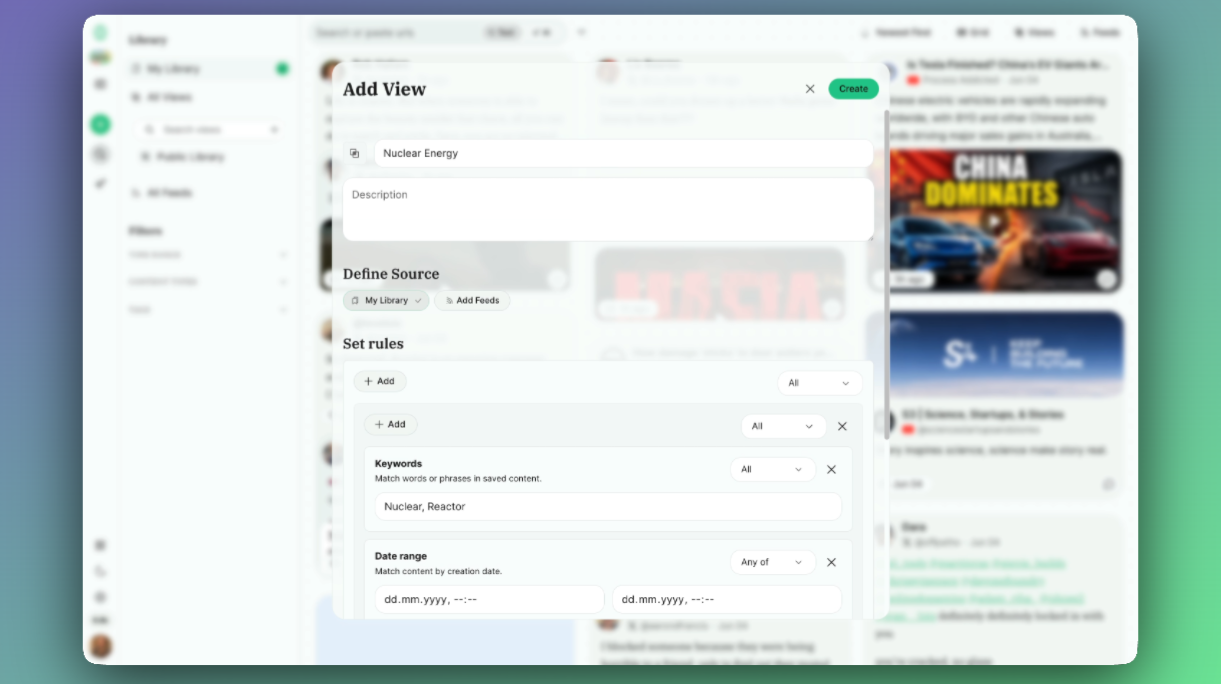
You can now create dynamic Views of things you saved. Say “in this view show me everything i tag with “#nuclear” or that has the terms “Nuclear” or “Reactor” in them” from the last 2 weeks.
This works across your own library or RSS feeds you follow.
The latter behind feature flag, settings > feature flags.
[Please report bugs via the help chat - they’ll be fixed within hours]

Features
Complex filter condition
You can create conditions for:
Keywords
Date Range
Tags
Content Types
And logic gates for nested:
All
Any
Not Any
Not All
Sharing Views
You can share views with other people and they can search & ask question on the filter scope you set. This makes it a low-friction way to share your reading list, research and notes.
This is already live but behind an early tester feature flag (settings > feature flags). A full change log for this will come soon.
Collaborative views
You can even collaborate on views with other people. If you invite someone to collaborate on a view and the accept that invitation, the same filter conditions will apply to their library and you have shared access to the conditions on that filter across multiple libraries.
This is already live but behind an early tester feature flag (settings > feature flags). A full change log for this will come soon.
Easter eggs / previews
Over the past 1.5 months we have been shipping a bunch of stuff that i am about to write change logs for. So if you’re playing around you can already find some of them. Others will be fully available in a few day when I polished them up. (If you find bugs, please report via the help chat, i am actively hunting for them and fixing them up right away)
Auto-Tagging saves & feeds
Mobile App to save, annotate, summarize & search
Summarizing X posts and videos from the timeline
Sharing Annotated pages
PDF annotation on mobile and desktop
@mentions on x to summarize/transcribe/translate
Sharing Views
Collaborative Views
Kindle import & sync
Readwise import & sync
RSS feeds: Follow, search and auto-tag incoming items
Importing YouTube channels
Importing everything from a page
Public Library so you can share publishable repositories of your work
Note to all Memex v1 users
If you’re just now coming back, Memex v2 is a completely new system. So sign up again, and if you had a lifetime plan prior, let me know via the help chat and I’ll upgrade you right away.
Either way, your existing data we will migrate over in the coming weeks, as our new data model stabilises (which we are almost there!)
~ Oliver
June 4th, 2026

Instead of confirming every highlight, you can toggle the auto-highlighter and every selected text becomes a highlight.
How to use it:
To activate use the tooltip menu or press the default “highlight” hotkey twice when no text is selected. Default: [alt/option]+[h]+[h]
If you only press [alt/option]+[h] when no text is selected the tooltip is toggled off.
[cmd/ctrl] + [Z] to undo last highlight(s)

June 2nd, 2026
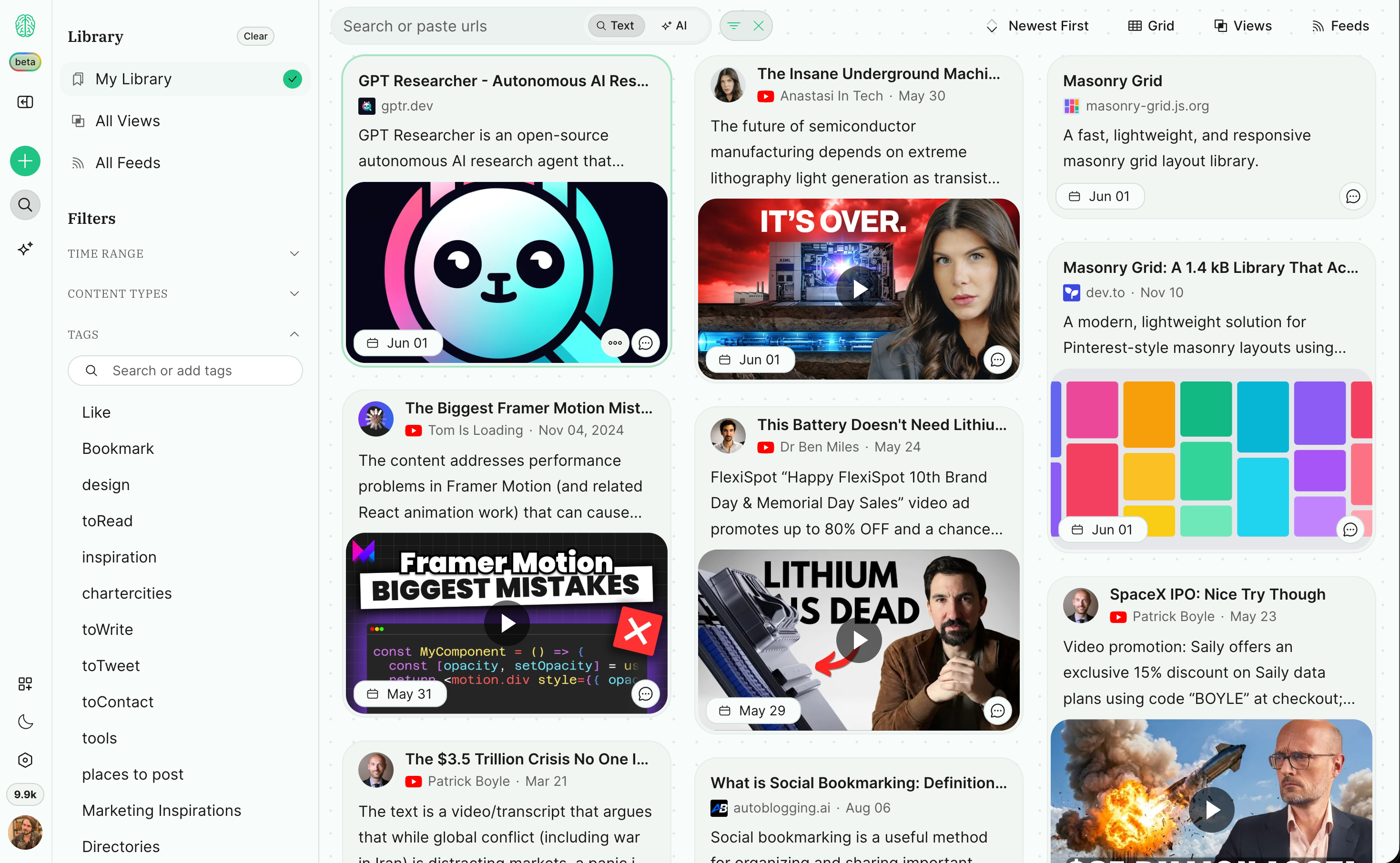
Woah. It’s been over a month since the last change log. We’ve been heads down shipping a whole series of improvements, fixes and updates (see very bottom for whats to come)
In the past 2 weeks we’ve put a lot of polishing efforts into the dashboard, so the first change log will go out for this and I am SOOOO excited for the next ones as well.
You can get to the dashboard by using [option/alt] + [shift] + [F] from any page, or visiting https://memex.garden/dashboard
[plz report bugs, we’ll fix them immediately]
Row/Grid view
Switch between grid/row view and set the # of columns

Split view (Search | AI chat)
The ability to have AI chat and search side by side.
[Shift] + click on either the “Search” or “Ask AI” button while the other one is already open.
Then drag & drop items from your search into the ai-chat.

Keyboard navigation & Hover Hotkeys
You can now use arrow keys to navigate through search results and hotkeys to interact with them. Just hover your cursor over the result and hit the hotkey.

Search Improvements
More Filters:
Exclusion filters for content types:
Just click twice on a content type to exclude it

All / Any / All not / Any not filters for tags
Click to toggle.

Split “Text” and “AI search” for faster search on known terms and more in-depth search on fuzzy queries

Greatly improved speed for fetching and searching
Spent an ungodly amount of time to make the loading sequence, result card expansions, row mode and pagination butter smooth.
New Themes
Light: Rose, Pen & Paper
Dark: Marine, Terminal

Note to all Memex v1 users
If you’re just now coming back, Memex v2 is a completely new system. So sign up again, and if you had a lifetime plan prior, let me know via the help chat and I’ll upgrade you right away.
Either way, your existing data we will migrate over in the coming weeks, as our new data model stabilises (which we are almost there!)
Easter eggs / previews
Over the past 1.5 months we have been shipping a bunch of stuff that i am about to write change logs for. So if you’re playing around you can already find some of them. Others will be fully available in a few day when I polished them up. (If you find bugs, please report via the help chat, i am actively hunting for them and fixing them up right away)
Auto-Highlighter & highlight toggle
Views
Auto-Tagging saves & feeds
Mobile App to save, annotate, summarize & search
Summarizing X posts and videos from the timeline
Sharing Annotated pages
PDF annotation on mobile and desktop
@mentions on x to summarize/transcribe/translate
Sharing Views
Collaborative Views
Kindle import & sync
Readwise import & sync
RSS feeds: Follow, search and auto-tag incoming items
Importing YouTube channels
Importing everything from a page
Public Library so you can share publishable repositories of your work
~ Oliver
April 28th, 2026
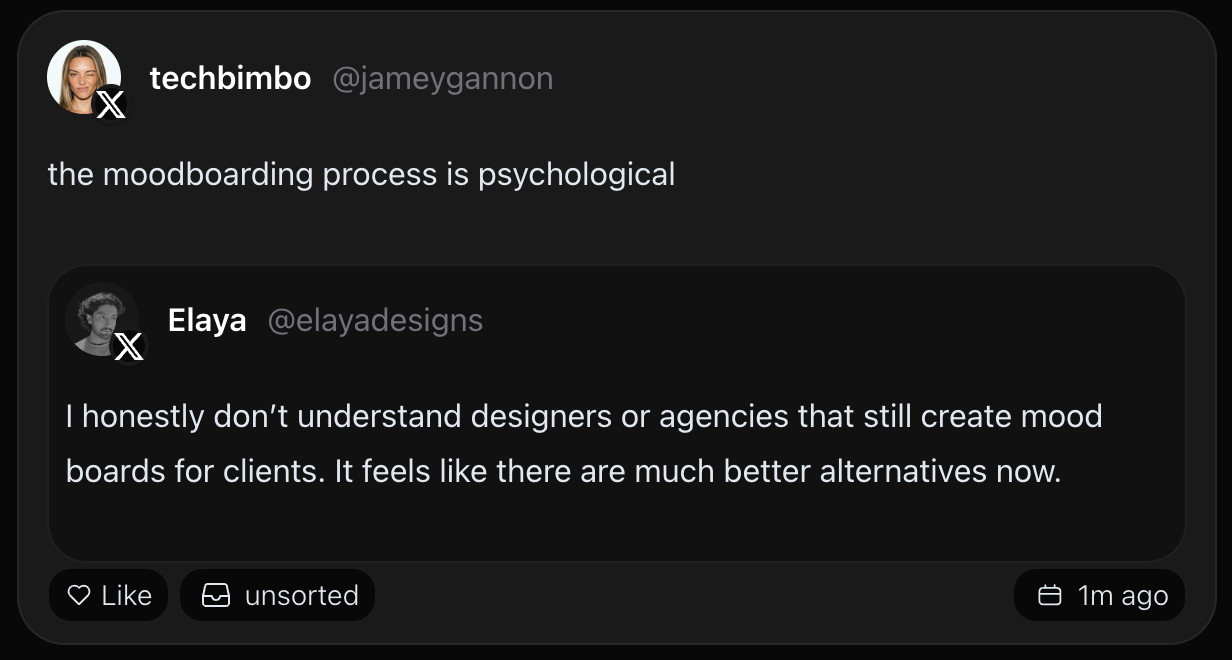
Now when you save a quote tweet, both the tweet and the quote tweet become searchable.
That even means you can search for the quote tweet content, and it will bring up the Quote tweet.

April 23rd, 2026

You can now use Memex within Claude Code/Cowork as a native plugin and use Memex as a bookmarking second brain.
Example Prompts.
Search my Memex library for pages about MCP authentication and summarize the top results.
Save https://docs.memex.garden/general/authentication into Memex, and tag it with #tutorials
Watch Quick Demo
How to install:
Download plugin: Download
Go to Claude's
CustomizetabPersonal Plugins>+icon >Create Plugin>Upload PluginSelect the zip
Select
Memex Garden Plugin>Connectors>ConnectFollow the OAuth flow
Optionally adjust tool permissions
You're done. You can now chat with Memex in your conversations.
April 22nd, 2026

Now you can search your Memex from inside Obsidian and copy/paste/drag cards into the editor. This is a first version and I’d love to hear from you how you think we can improve it.
Features:
Search Memex from the sidebar
Copy/Paste or Drag/Drop any result card from Memex sidebar into editor
Open result card result (click)
View notes/related content to the current content in the Memex sidebar (shift+click)
Video demo:
How to install
Via Dashboard

Via Action Bar:

Upcoming improvements:
Inline display of search results
If you ever want to write notes and have a list of e.g. “All things I saved that match the keyword “nuclear” and have the tag #research”
Search your Obsidian Graph in and outside of Memex
Use our Obsidian documents in the search and the AI chat.
Auto-updating cards
Content and notes you reference auto-update their content after changes in Memex.
April 6th, 2026
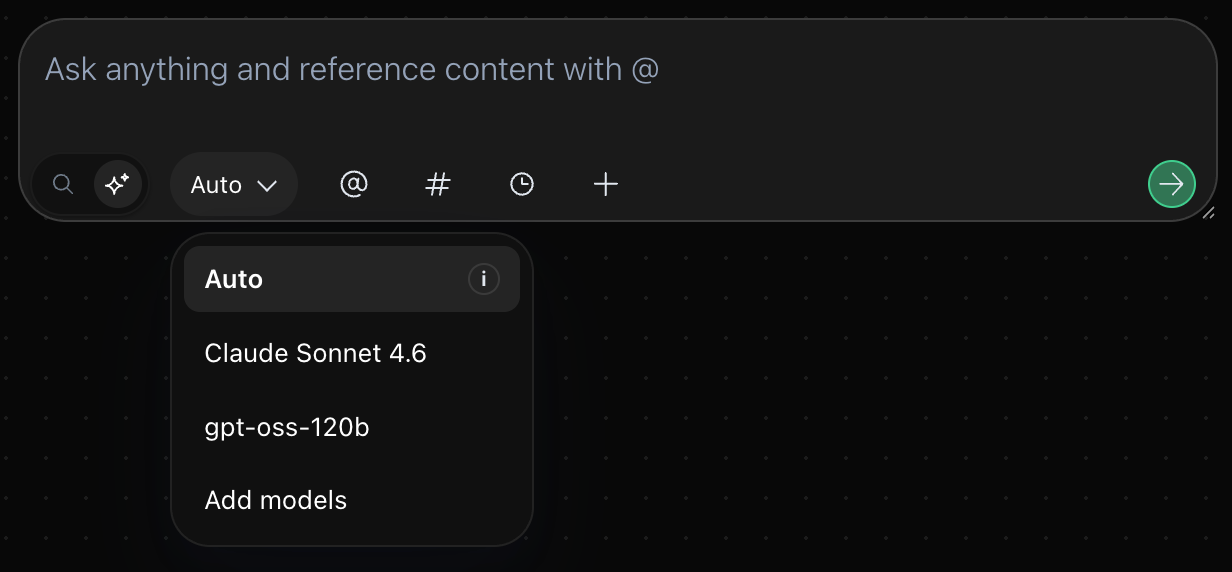
You can now select any custom model from the Openrouter.ai pool, if you provide your own API key.
Search any model on OpenRouter

Pricing changes when bringing your own key
When you bring your own API key, you’re only charge for AI chat turns (3 credits per turn) and not anymore for the consumed tokens (currently 300 credits per 1m input/output tokens)
Previous feature updates:
April 5th, 2026
New
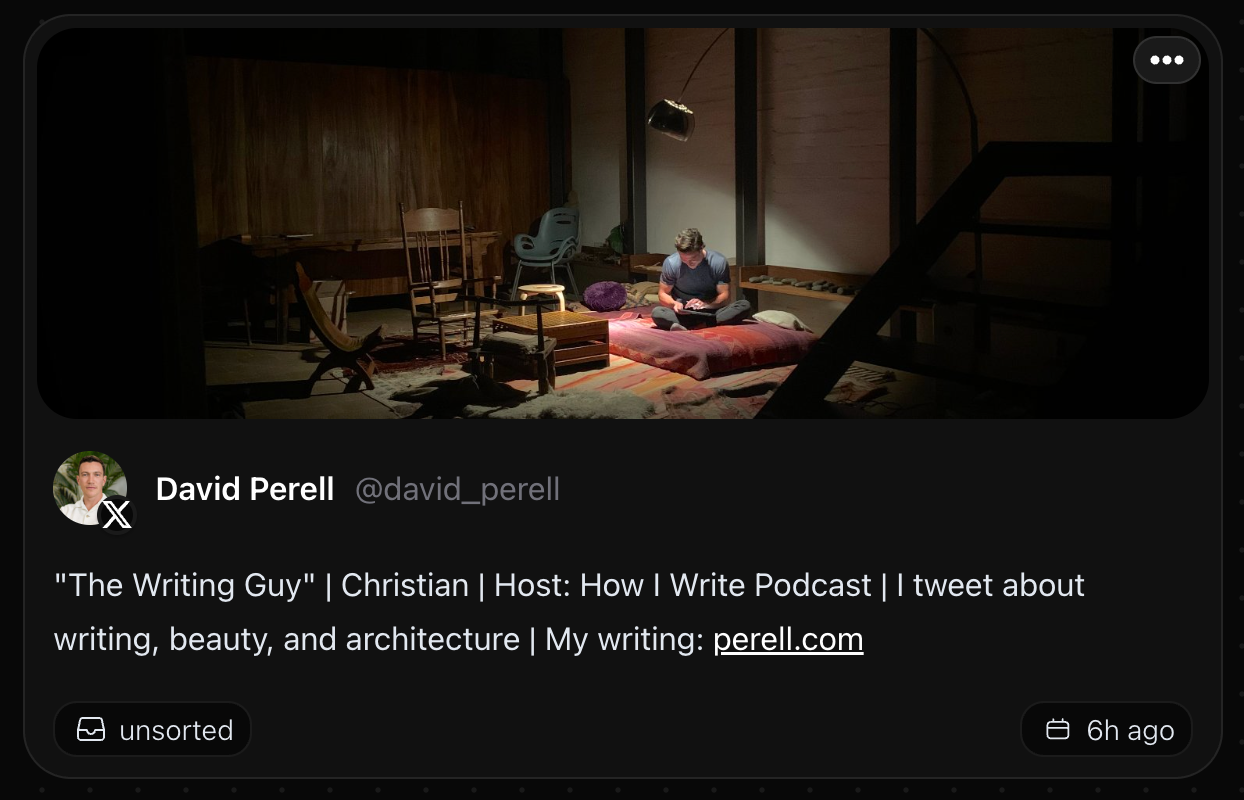
We’ve added support for a bunch of content types to save and search.
»»» TELL ME WHAT OTHER TYPES YOU WANT US TO SUPPORT VIA THE CHAT! «««
~ Oliver
PS: Download the new v2 extension here. Mind that its a completely new system and we are going to migrate over v1 accounts once v2 stabilises.
X profiles
X profiles are now first class citizens that can be saved, indexed and searched.
We’ll likely also add the ability to index anyone you follow so you have a searchable graph of people you find interesting.

X video transcripts
Now all videos and also referenced YouTube videos that are part of a X post are also fully transcribed and part of your searchable data.

Tiktok videos:
Now indexes the cover image and transcripts of every TikTok video you save and makes its available via search & API

Facebook posts
You can now save & annotate Facebook posts. That only works on posts that are publicly accessible - which unfortunately limits the effectiveness of this feature.
If demand is there we’ll improve that to also include private posts but that is a bit more involved.

Images
In the dashboard you can now drag & drop images into, they are fully described, text-extracted, indexed and available via search & API

Previous feature updates:
March 12th, 2026

In the past month our updates were a bit quiet as we’ve been heads down completely rebuilding our database and search infrastructure for a consistent search experience across all current and future touch points.
This update was massive migration from Firebase to Supabase touching every part of our codebase, so please reach out asap if you are running into any issues whatsoever.
PS: If you are an existing subscriber and have not migrated to Memex v2, please reach out so i can port your subscription.
~ Oliver
Features:
Search Memex from anywhere
You can search your saved Memex content from anywhere with full text and semantic search
Mobile App (already in review)
Obsidian Integration (in development)
N8N plugin (coming soon)
Indexing URLs
You can now use the API, MCP, Claude/OpenClaw skills to save urls into your knowledge base, see documentation linked in previous point.
Supports public websites, tweets, YouTube videos, images and you can also add tags to everything you save via the API.
Some notes:
This is just the beginning of making Memex’ search really good and we have many improvements planned (e.g. entity recognition, graph retrieval, better chunking etc). Please reach out with concrete examples of searches that don’t fullfil the way you want it so we understand the limitations and can improve on them
Cool side effect of this work: Moving to Supabase will open the path to self-hostability on an open source infrastructure. Not promising anything at this point there are other priorities but its possible.
Claude Plugin & OpenClaw skills
Now we have dedicated support not just as an MCP/API endpoint but for Claude Plugins, OpenClaw skill and al other agent frameworks that can read skills and mcp endpoints.
Visit our docs to get started »
Quality of Life improvements
Much faster Youtube transcript fetching and summarisation
Showing date of saved items in results and adjust time formats via the settings

Unifying profile picture and social source flags

Speed improvements to search
Some design improvements for cleaner design
Other:
New Landingpage: https://memex.garden
